[TOC]
PE文件结构
PE : Portable Executable 可移植的可执行文件,Windows 操作系统下的可执行文件(exe,scr)、动态链接库(dll,oxc,cpl)、驱动程序(sys,vxd)的总称
DOS头:DOS Header + DOS Stub
DOS Header 结构体(0x40),用于向后兼容早期的 MS-DOS
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE 文件头结构体
WORD e_magic; // 标识符,用于确认这是MZ格式的文件,值为0x5A4D
WORD e_cblp; // 文件中最后一个扇区的字节数
WORD e_cp; // 文件中的扇区总数
WORD e_crlc; // 重定位表中的条目数
WORD e_cparhdr; // 文件头的大小,以16字节为单位
WORD e_minalloc; // 程序加载时所需的最小额外内存段落数
WORD e_maxalloc; // 程序加载时所需的最大额外内存段落数
WORD e_ss; // 初始堆栈段选择子(段地址)
WORD e_sp; // 初始堆栈指针值
WORD e_csum; // 校验和,用于检验文件的完整性
WORD e_ip; // 初始指令指针(IP值)
WORD e_cs; // 初始代码段选择子(段地址)
WORD e_lfarlc; // 文件中重定位表的偏移量
WORD e_ovno; // 覆盖号,用于实现覆盖功能
WORD e_res[4]; // 保留字段,供未来使用
WORD e_oemid; // OEM标识符,用于特定于OEM的扩展
WORD e_oeminfo; // OEM信息,供OEM使用
WORD e_res2[10]; // 保留字段,供未来扩展使用
LONG e_lfanew; // 指向新EXE(PE)头的偏移量,从文件开始处计算
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;重点关注:
- e_magic:位于文件首,确认是 MZ 格式文件,对应 ascii 的 MZ
- e_lfanew:PE 头偏移地址,e_lfanew = 80,对应 0080h 处
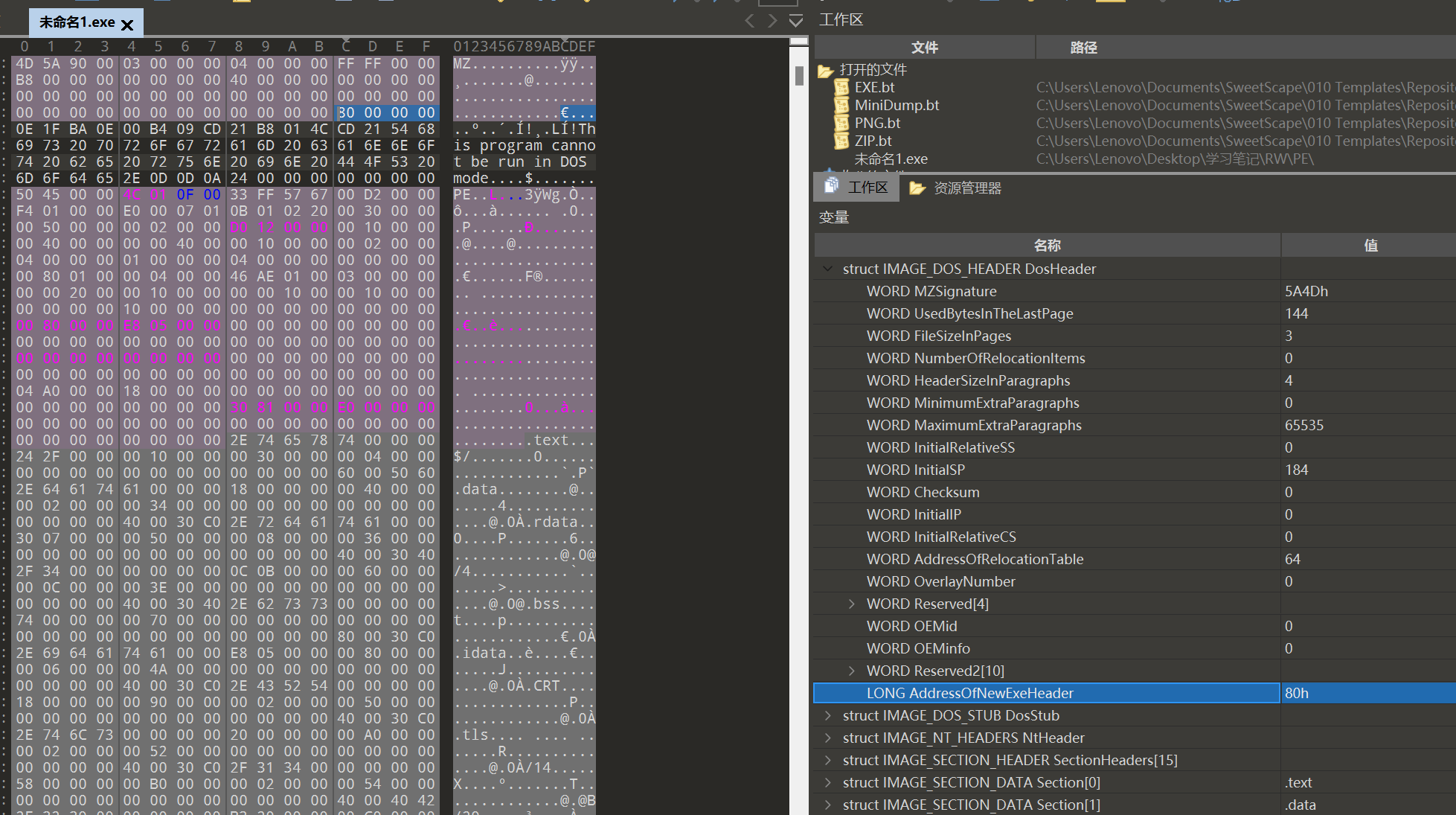
DOS Stub 编译器自动生成,由代码和数据混合而成,大小不固定,在不支持 PE 文件格式的操作系统中会显示一个错误提示,在 Windows 中不运行,在 DOS 中会运行
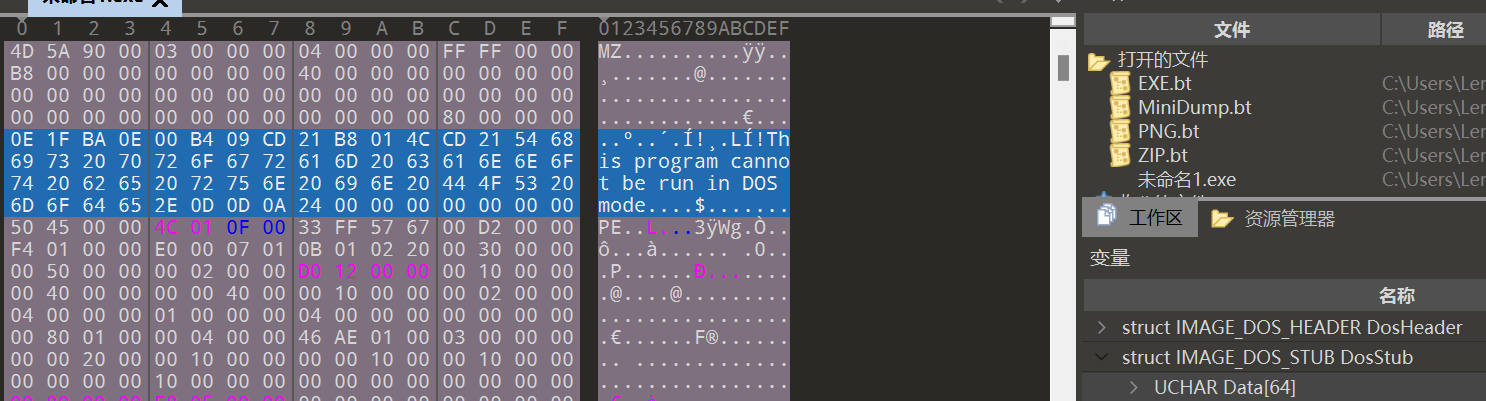
PE 头: NT 头 + 节表区
NT头
PE 文件的核心部分,包含关于可执行文件的重要信息。开始位置由 e_lfanew 指定
32位中 NT 结构体 _IMAGE_NT_HEADERS 如下(0xf8):
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature; // PE签名,0x4字节
IMAGE_FILE_HEADER FileHeader; // PE头,0x14字节
IMAGE_OPTIONAL_HEADER32 OptionalHeader; // PE可选头
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;PE 头结构体 _IMAGE_FILE_HEADER 如下:
typedef struct _IMAGE_FILE_HEADER {
WORD Machine; // 目标机器的类型码,如x86或ARM
WORD NumberOfSections; // 文件中节(section)的数量
DWORD TimeDateStamp; // 文件创建或最后修改的时间戳
DWORD PointerToSymbolTable; // 指向文件中符号表的偏移地址
DWORD NumberOfSymbols; // 符号表中符号条目的数量
WORD SizeOfOptionalHeader; // 可选头的大小,用于存储扩展的文件信息
WORD Characteristics; // 文件特性标志,指DLL、应用程序、可执行文件等
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;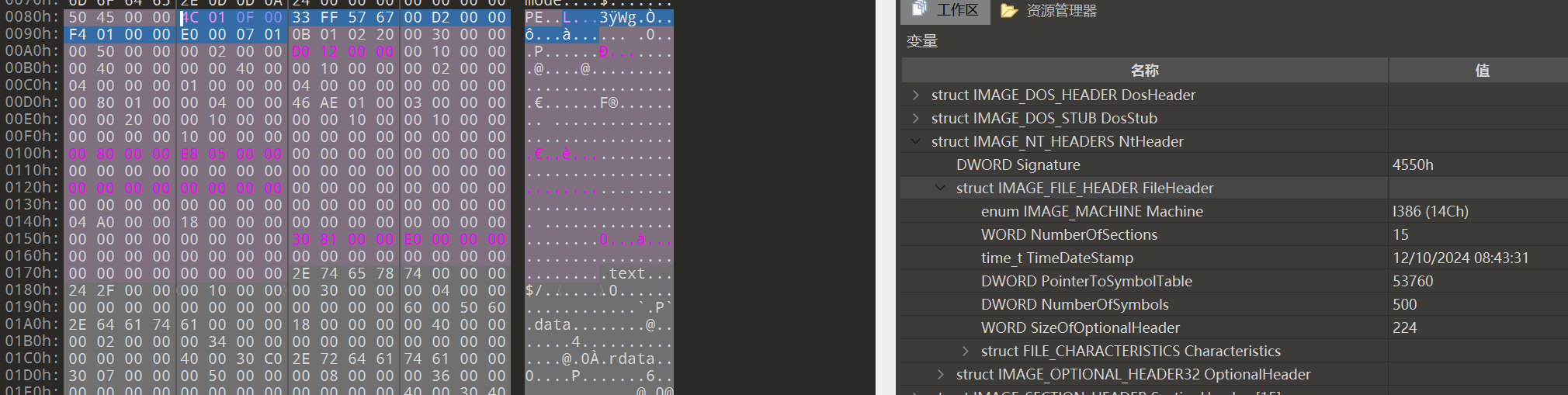
PE 可选头结构体 _IMAGE_OPTIONAL_HEADER 如下:
#define IMAGE_NUMBEROF_DIRECTORY_ENTRIES 16 // 数据目录项数,固定为16
typedef struct _IMAGE_OPTIONAL_HEADER {
// 标准域
WORD Magic; // 可选头类型,0x10表示32位,0x20表示64位
BYTE MajorLinkerVersion; // 主链接器的版本号,以字节为单位
BYTE MinorLinkerVersion; // 副链接器的版本号,以字节为单位
DWORD SizeOfCode; // 代码段大小,以字节为单位
DWORD SizeOfInitializedData; // 初始化数据段大小,以字节为单位
DWORD SizeOfUninitializedData; // 未初始化数据段大小,以字节为单位
DWORD AddressOfEntryPoint; // 程序入口点地址,相对于ImageBase
DWORD BaseOfCode; // 代码段起始基址RVA
DWORD BaseOfData; // 数据段起始基址RVA
// NT附加域
DWORD ImageBase; // 镜像基址,即加载到内存的起始地址
DWORD SectionAlignment; // 节在内存中的对齐大小,以字节为单位
DWORD FileAlignment; // 节在文件中的对齐大小,以字节为单位
WORD MajorOperatingSystemVersion; // 主操作系统版本号
WORD MinorOperatingSystemVersion; // 副操作系统版本号
WORD MajorImageVersion; // 主镜像版本号
WORD MinorImageVersion; // 副镜像版本号
WORD MajorSubsystemVersion; // 主子系统版本号
WORD MinorSubsystemVersion; // 副子系统版本号
DWORD Win32VersionValue; // Win32版本值,通常为0
DWORD SizeOfImage; // 镜像在内存中的大小,以字节为单位
DWORD SizeOfHeaders; // PE头物理大小,以字节为单位
DWORD CheckSum; // 校验和,用于验证镜像的完整性
WORD Subsystem; // 子系统类型
WORD DllCharacteristics; // DLL特性标志,指示文件是DLL、应用程序等
DWORD SizeOfStackReserve; // 运行时为每个线程栈保留的内存大小
DWORD SizeOfStackCommit; // 运行时每个线程栈初始占用的内存大小
DWORD SizeOfHeapReserve; // 运行时为进程堆保留的内存大小
DWORD SizeOfHeapCommit; // 运行时进程堆初始占用的内存大小
DWORD LoaderFlags; // 载入器标志,通常为0
DWORD NumberOfRvaAndSizes; // 数据目录的项数,固定为IMAGE_NUMBEROF_DIRECTORY_ENTRIES的值
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]; // 数据目录数组
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;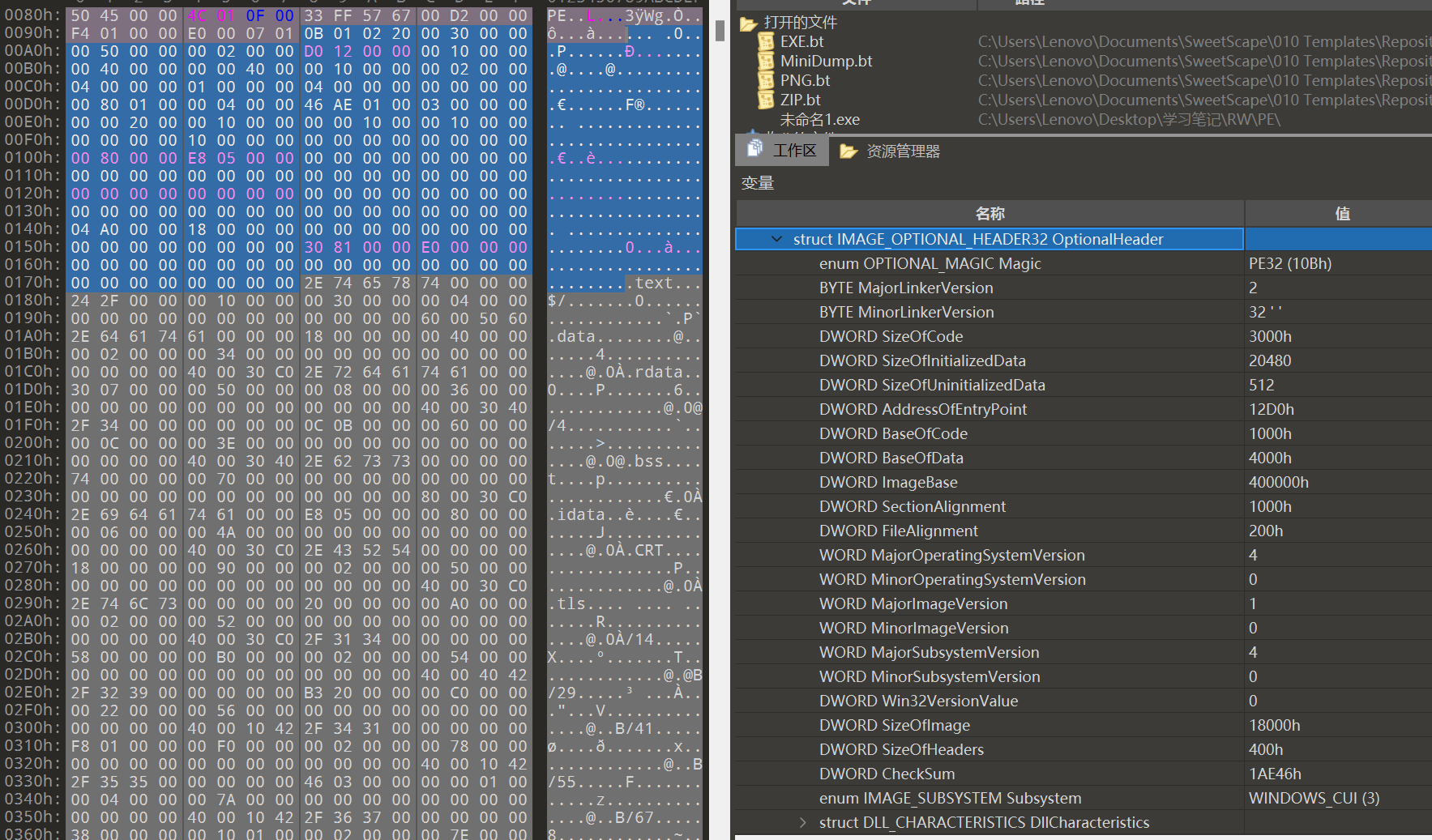
节表区
描述 PE 文件各个节的布局和属性,位于 NT 头之后,由一系列 IMAGE_SECTION_HEADER 结构(0x28)构成,每个结构描述一个节,结构排序顺序和描述的节在文件中排序顺序一致。最后以一个空结构结束,所以节表中结构数量为节数量加一
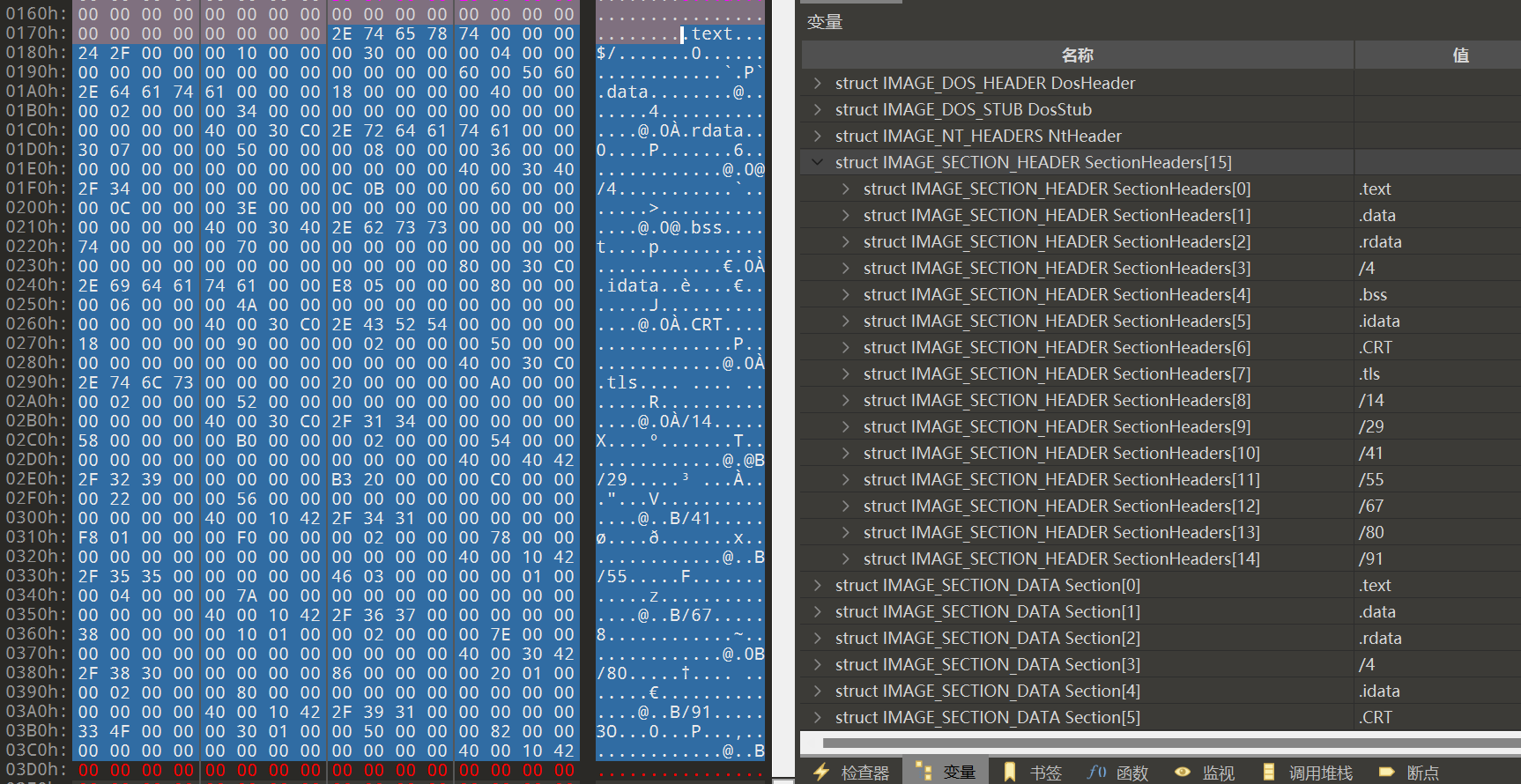
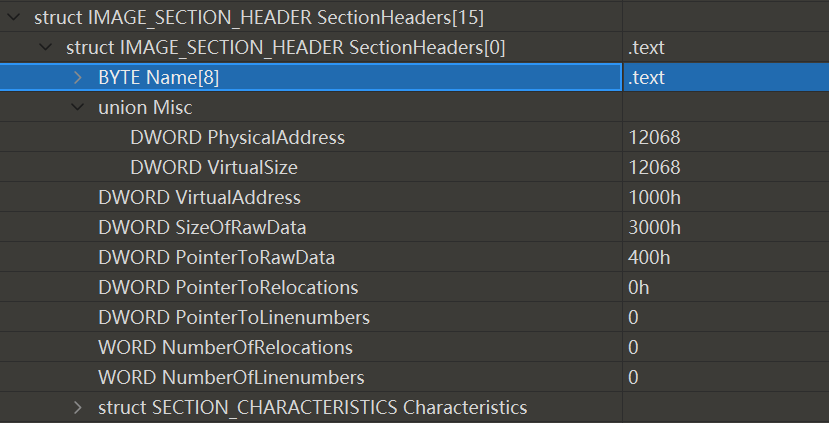
其余特定区域
text 节、data 节、rsrc 节、数据目录表、导入表、导出表、资源表、重定位表、自定义部分、tls表(线程局部存储表)、加载配置表等
.relocation 节前 8 字节记录节的 RVA 和需要进行重定位或修改的条目数量,每一项都记录了哪些 RVA 地址下的硬编码寻址在加载进内存时是需要进行重定位的
RVA: PE文件的相对虚拟地址(Relative Virual Address)是PE文件中的数据、模块等运行在内存中的实际地址相对PE文件装载到内存的基址之间的距离
导入表 导出表
导入表:存在多个导入表记录每个模块,记录自身使用到的其他模块导出的函数,用于确定调用了哪些模块(dll)的哪些函数,以及确定模块加载进内存后具体函数的地址
导入表结构体(0x14)如下:
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA) 指向IAT结构
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 时间戳.
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name; //指向 DLL 名字的 RVA 地址
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;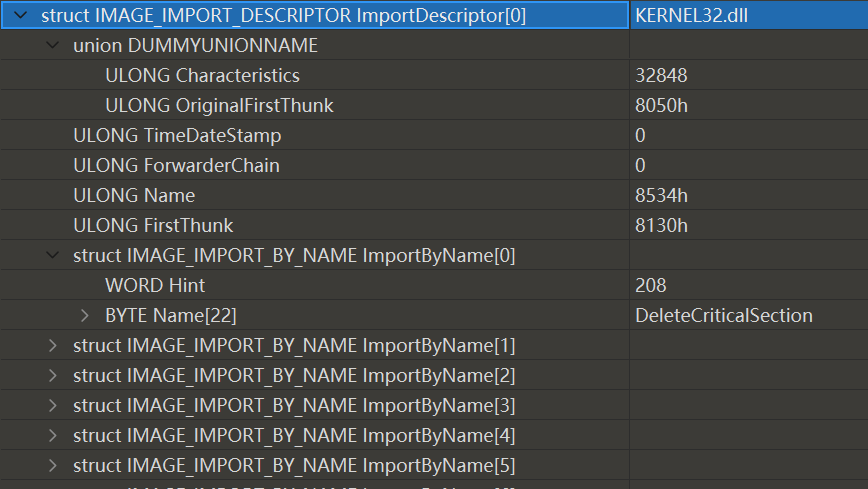
结构体成员:
DUMMYUNIONNAME
用于确定依赖函数的名称,指向 INT (导入名称表)
FirstThunk
指向 IAT 导入地址表,类似 got 表

Name
记录一个 RVA 地址,指向依赖的模块的名字
导出表:只有一个,有子表记录导出符号的地址、名称、序号,需要提供功能的二进制程序(dll)才会有导出表
包含信息:
- 动态链接库提供了什么功能
- 向调用者提供输出函数(供使用者调用的函数)在模块中的起始地址
利用:通过 dll 名和 dll 导出函数名得到函数地址,也可以通过代码获取:
- 通过 Loadlibrary(GetModelHandle) 将 dll 模块映射进内存并返回一个可以被 GetProcAddress 函数使用的句柄
- 利用 GetProcAddress 函数获得 dll 的加载地址,然后遍历导出表就可以得到函数地址
判断导出函数是以序号导出还是以名称导出:
遍历序号表,判断地址表的下标有没有存在与序号表中,存在就说明是以名称导出,不存在就说明是以序号导出
PE文件压缩实操总结
(原理见链接博客
原程序基址 400000, text 段偏移 1000,rdata 段偏移 2000, data 段偏移 3000
删除部分
DOS头从头到 e_lfanew(AddressOfNewExeHeader) 保留其余删除, nt 头到 text 段、text 段到 rdata 段之间多余 \x00 删除,rdata 段末尾保留 4 * \x00 截断字符串,截断字符串到 data 段多余的 \x00 删除
(删除 nt 头到 text 段的全部 \x00 会报WARNING Line 84: 空结构 和 ERROR Line 1367: 声明中的数组大小无效 的错误但是能运行,不过建议最后熟悉了再删不然影响 010 的 exe模板识别后面节表)
修改部分
DosHeader 中 e_lfanew(AddressOfNewExeHeader) 指向 010 中 pe地址
NtHeader 中的 OptionalHeader:
AddressOfEntryPoint 指向 010 中 text 段地址
SectionAlignment 、 FileAlignment 改成 4(最小对齐长度)
SectionHeaders 中每个节 VirtualAddress 、PointerToRawData 改成 010 中该节地址,SizeOfRawData 改成该节大小
按偏移修改部分
NtHeader -> OptionalHeader -> DataDirArray 中的 Import 和 ImportAddressTable
text 段、rdata 段、data 段中涉及地址的地方(形如402000 / 2000的绝对地址或相对地址,具体看原程序在 ida 中哪里是地址)根据 SectionHeaders 中的地址得到偏移再计算修改后的地址
例如: Import 原值是 2010,所以属于 rdata 段,基址 2000,偏移 10,rdata 段修改后基址 1f0, 所以 Import 需要修改成 1f0 + 10,注意不要算错
PE文件注入
*改之前记得先备份一份
总体思路
弹出窗口用到了MessageBoxA函数,用法如下
int __stdcall MessageBoxA(HWND hWnd, LPCSTR lpText, LPCSTR lpCaption, UINT uType)该函数的二参是弹窗内容,三参是弹窗标题,本文最终目标就是构造出:
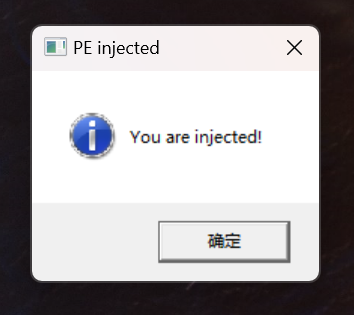
MessageBoxA(0LL, "You are injected!", "PE injected", 0x1040u);弹出标题为 PE injected 内容为 You are injected!,所以总体思路就是先写入标题和内容的字符串,再将参数传递给对应寄存器,最后调用 MessageBoxA 函数
写入字符串
向 rdata 段末尾写入 PE injected 和 You are injected!,这里直接用 ida 修改可能会无法保存,需要用 010 editor 写入字符串:先在 ida 中找到 rdata 末尾位置,在 010 editor 中直接搜索字符串 InitializeSListHead 定位到 rdata 段末尾,在后面添加 PE injected 和 You are injected!,再用 ida 打开就能在 rdata 段末尾看到写入的字符串
确定字符串偏移
由于程序开了地址随机化,所以不能直接根据地址获取字符串的位置,这里可以参考原程序中字符串是如何获取地址的,例如 19 行的 xmmword_140005820 就是 rdata 段的一个变量
程序中获取地址的相关代码:
movdqa xmm0, cs:xmmword_140005820直接看movdqa xmm0, cs:xmmword_140005820对应的字节码是66 0F 6F 05 DE 40 00 00,反编译结果如下,也就是使用 rip 加偏移获取的相对地址
movdqa xmm0, xmmword ptr [rip+0x40de]而这里的 xmmword_140005820 在 ida 中的地址是 0x140005820,上面 010 editor 写入的字符串地址是 0x140006D00,但是由于指令位置不同,同一个变量对应于 rip 的偏移也不同,所以需要结合指令地址去计算字符串的地址,或者直接填一个 rdata 段的地址再根据得到的位置多减少补
添加 MessageBoxA 函数
程序中原本是没有 MessageBoxA 函数的,但是在 idata 段有 MessageBoxA 外部函数,所以不能直接通过call MessageBoxA去调用这个函数,需要手动添加MessageBoxA函数,添加内容可以参考exit函数,函数的功能是跳转到 idata 段的对应函数
jmp cs:__imp_exit对应字节码:FF 25 C8 0D 00 00,同样也是通过 rip 进行相对寻址
jmp qword ptr [rip + 0xdc8]所以添加 MessageBoxA 函数的方式也类似,需要向 text 段末尾添加跳转函数,这里和添加字符串一样,直接用 ida 添加可能会保存失败,需要先用 010 editor写入一段跳转代码的字节码,添加完成后再用 ida 修改是可以正常保存的,所以偏移不确定可以先随机添加一个地址(参考其他函数中使用的地址确保添加的地址位于 idata 段的范围方便后续计算调试),再用 ida 根据添加的函数地址和 MessageBoxA 的相对位置用 Change Byte 去调整具体地址即可
最终构造如下函数:
jmp cs:__imp_MessageBoxA这样就可以直接call MessageBoxA调用该函数
注入代码
将代码写到开栈操作sub rsp, 0E0h的后面,否则会堆栈不平衡
将汇编翻译成字节码,这里字符串的相对地址是根据上述方式大致确定的地址,将字节码通过 Change Byte 修改(用 ida 的 assembly 修改会报 Invalid operand
mov r9, 1040h lea r8, [rip + 0x5662] lea rdx, [rip + 0x5663] mov rcx, 0得到字节码:
49 c7 c1 40 10 00 00 4c 8d 05 62 56 00 00 48 8d 15 63 56 00 00 48 c7 c1 00 00 00 00根据得到的字符串位置和实际写入的字符串位置在 ida 中使用 Change Byte 对地址进行微调直到找到正确地址
在添加的汇编代码最后使用 ida 的 assemble 添加
call MessageBoxA按 tab 确认反编译结果是不是
MessageBoxA(0LL, "You are injected!", "PE injected", 0x1040u);
最终效果
相关链接
还是我ve1宝哒Ovo
