十天速通kernel基础理论了属于是…画了个思维导图加深一下印象
ROP(returned oriented programming)
ROP
构造commit_creds(&init_cred) 或 commit_creds(prepare_kernel_cred(NULL))
kallsyms中存在commit_creds和prepare_kernel_cred函数地址init中dmesg_restrict=1时不能使用dmesg查看kernel信息
状态保存
保存各寄存器的值到内核栈上便于后续回到用户态,模板如下,编译时指定参数-masm=intel
size_t user_cs, user_ss, user_rflags, user_sp;
void saveStatus()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
puts("\033[34m\033[1m[*] Status has been saved.\033[0m");
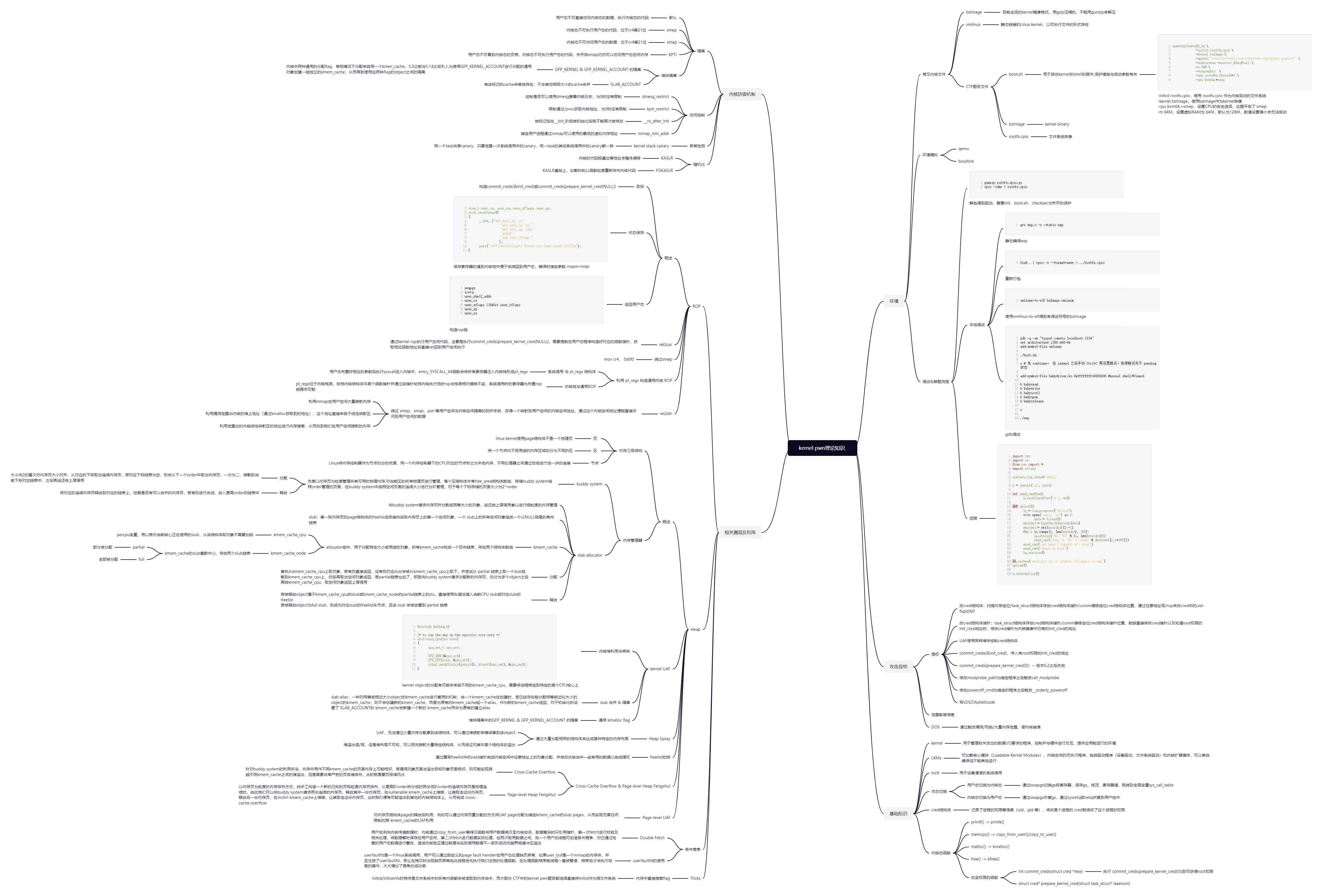
}返回用户态
swapgs指令恢复用户态GS寄存器sysretq或者iretq恢复到用户空间
那么我们只需要在内核中找到相应的 gadget 并执行swapgs;iretq就可以成功着陆回用户态。
通常来说,我们应当构造如下 rop 链以返回用户态并获得一个 shell:
↓ swapgs
iretq
user_shell_addr
user_cs
user_eflags //64bit user_rflags
user_sp
user_ssret2usr
smap/smep未开启的时候内核可以访问执行用户空间数据,所以可以通过kernel rop以内核ring 0权限执行用户空间代码,主要是执行commit_creds(prepare_kernel_cred(NULL)),需要提前在用户态程序构造好对应的函数指针、获取相应函数地址后直接ret回到用户空间执行
bypass-smep
SMEP
为了防止 ret2usr 攻击,内核开发者提出了 smep 保护,当 CPU 处于 ring0 模式时,执行用户空间的代码会触发页错误,这个保护在 arm 中被称为 PXN
smep 和 CR4 寄存器
系统根据 CR4 寄存器的值判断是否开启 smep 保护,当 CR4 寄存器的第 20 位是 1 时,保护开启,是 0 时,保护关闭
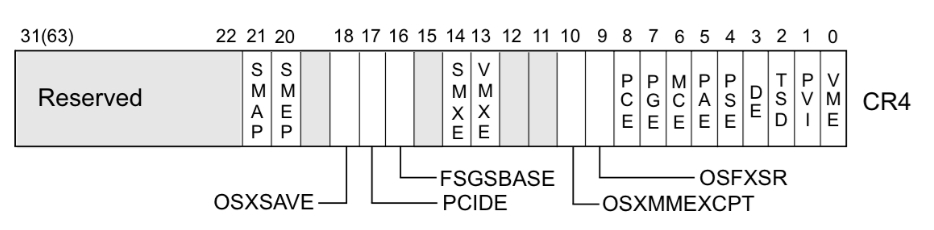
CR4 寄存器可以通过 mov 指令修改cr4来关闭smep保护
mov cr4, 0x1407e0
# 0x1407e0 = 101 0 0000 0011 1111 00000搜索一下从 vmlinux 中提取出的 gadget,很容易就能达到这个目的
- 查看
CR4寄存器的值gdb无法查看cr4寄存器的值,可以通过kernel crash时的信息查看。为了关闭smep保护,常用一个固定值0x6f0,即mov cr4, 0x6f0
利用 pt_regs 构造通用内核 ROP
系统调用 与 pt_regs 结构体
系统调用:用户态布置好相应的参数后执行 syscall 进入到内核中的 entry_SYSCALL_64,随后通过系统调用表跳转到对应的函数
entry_SYSCALL_64 :当程序进入到内核态时,该函数会将所有的寄存器压入内核栈上,形成一个 pt_regs 结构体,该结构体实质上位于内核栈底
struct pt_regs {
/*
* C ABI says these regs are callee-preserved. They aren't saved on kernel entry
* unless syscall needs a complete, fully filled "struct pt_regs".
*/
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long rbp;
unsigned long rbx;
/* These regs are callee-clobbered. Always saved on kernel entry. */
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long rax;
unsigned long rcx;
unsigned long rdx;
unsigned long rsi;
unsigned long rdi;
/*
* On syscall entry, this is syscall#. On CPU exception, this is error code.
* On hw interrupt, it's IRQ number:
*/
unsigned long orig_rax;
/* Return frame for iretq */
unsigned long rip;
unsigned long cs;
unsigned long eflags;
unsigned long rsp;
unsigned long ss;
/* top of stack page */
};内核栈与通用ROP
内核栈只有一个页面的大小,而 pt_regs 结构体则固定位于内核栈栈底,劫持内核结构体中的某个函数指针(例如 seq_operations->start)并通过该函数指针劫持内核执行流时 rsp 与 栈底的相对偏移通常是不变的
系统调用过程中的这些寄存器为我们布置 ROP 链提供了可能,只需要寻找到一条形如 add rsp, val ; ret 的 gadget 便能够完成 ROP
模板:
__asm__(
"mov r15, 0xbeefdead;"
"mov r14, 0x11111111;"
"mov r13, 0x22222222;"
"mov r12, 0x33333333;"
"mov rbp, 0x44444444;"
"mov rbx, 0x55555555;"
"mov r11, 0x66666666;"
"mov r10, 0x77777777;"
"mov r9, 0x88888888;"
"mov r8, 0x99999999;"
"xor rax, rax;"
"mov rcx, 0xaaaaaaaa;"
"mov rdx, 8;"
"mov rsi, rsp;"
"mov rdi, seq_fd;" // 这里假定通过 seq_operations->stat 来触发
"syscall"
);新版本内核中为系统调用栈添加了一个偏移值,这意味着 pt_regs 与我们触发劫持内核执行流时的栈间偏移值不再是固定值,在这个随机偏移值较小且我们仍有足够多的寄存器可用的情况下,仍然可以通过布置一些 slide gadget 来继续完成利用,不过稳定性也大幅下降了
ret2dir
主要用来绕过 smep、smap、pxn 等用户空间与内核空间隔离的防护手段
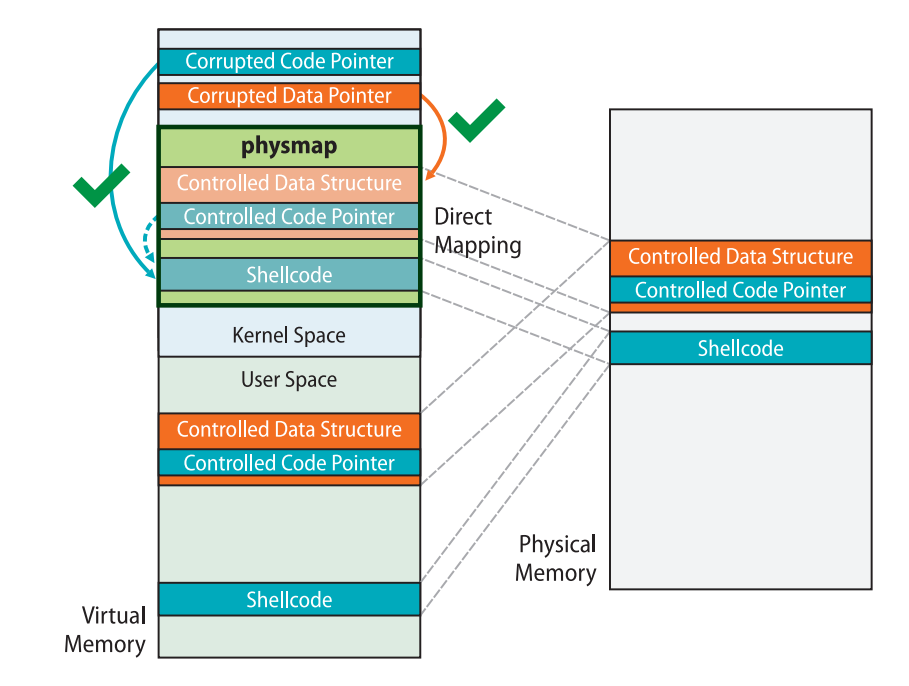
我们首先来思考一下 x86 下的 Linux kernel 的内存布局,存在着这样的一块区域叫做 direct mapping area,线性地直接映射了整个物理内存空间:
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)这块区域的存在意味着:对于一个被用户进程使用的物理页框,同时存在着一个用户空间地址与内核空间地址到该物理页框的映射,即我们利用这两个地址进行内存访问时访问的是同一个物理页框
当开启了 SMEP、SMAP、PXN 等防护时,内核空间到用户空间的直接访问被禁止,我们无法直接使用类似 ret2usr 这样的攻击方式,但利用内核线性映射区对整个物理地址空间的映射,我们可以利用一个内核空间上的地址访问到用户空间的数据,从而绕过 SMEP、SMAP、PXN 等传统的隔绝用户空间与内核空间的防护手段
下图是ret2dir 的示例,在用户空间中布置的 gadget 可以通过 direct mapping area 上的地址在内核空间中访问到:
新版的内核当中 direct mapping area 已经不再具有可执行权限,因此很难在用户空间直接布置 shellcode 进行利用,但仍能通过在用户空间布置 ROP 链的方式完成利用:
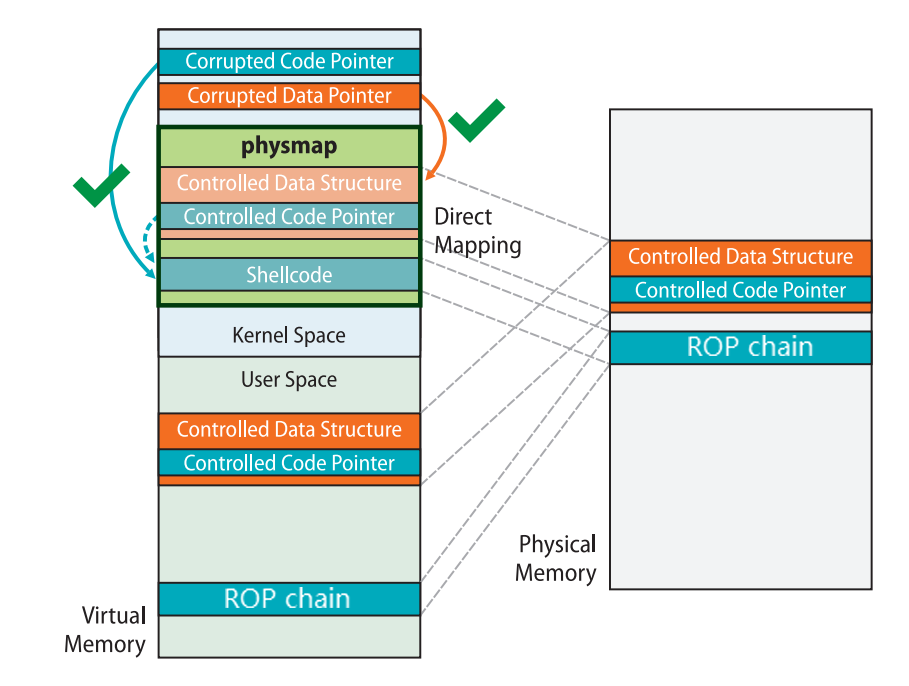
ret2dir 攻击的手法:
- 利用
mmap在用户空间大量喷射内存 - 利用漏洞泄露出内核的 “堆” 上地址(通过
kmalloc获取到的地址),这个地址直接来自于线性映射区 - 利用泄露出的内核线性映射区的地址进行内存搜索,从而找到我们在用户空间喷射的内存
此时获得了一个映射到用户空间的内核空间地址,通过这个内核空间地址便能直接访问到用户空间的数据,避开传统的隔绝用户空间与内核空间的防护手段
需要注意的是我们往往没有内存搜索的机会,因此需要使用 mmap 喷射大量的物理内存写入同样的 payload,之后再随机挑选一个线性映射区上的地址进行利用,这样就有很大的概率命中到我们布置的 payload 上,这种攻击手法也称为 physmap spray
Heap
概述
内存三级结构

页-
pagelinux kernel使用page结构体表示一个物理页,对应图中结构体page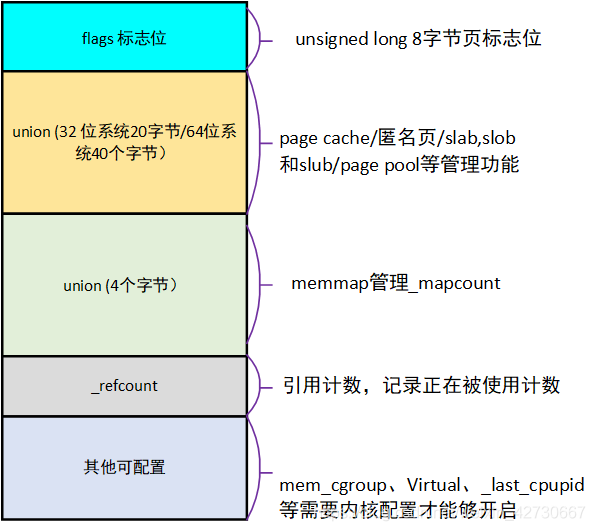
区-
zonelinux将一个节点内不同用途的内存区域划分为不同的区,对应图中结构体zone
节点-
nodeLinux将内存控制器(memory controller)作为节点划分的依据,同一个内存控制器下的CPU对应的节点称之为本地内存,不同处理器之间通过总线进行进一步的连接,对应图中结构体pgdata_list
内存管理器
buddy system负责以内存页为粒度管理所有可用的物理内存,存在于区级别,对当前区的所有物理页进行管理,每个区
zone结构体中有free_area结构体数组,存储buddy system按照order管理的页面,其中MAX_ORDER = 11struct zone { //... struct free_area free_area[MAX_ORDER]; //...在
buddy system中按照空闲页面的连续大小进行分阶管理,这里的order的实际含义为连续的空闲页面的大小,单位是阶,即对于每个下标存储的页面大小为2^order,参考区结构体的图分配:
大小向
2的幂次方内存页大小对齐,从对应的下标取出连续内存页,若对应下标链表为空,则会从下一个order中取出内存页,一分为二,装载到当前下标对应链表中,之后再返还给上层调用释放:
将对应的连续内存页释放到对应的链表上,检索是否有可以合并的内存页,若有则进行合成,放入更高
order的链表中
slab allocator向
buddy system请求内存页(sllub)并分割成同等大小的对象(object,被分配实体)返还给上层调用者以进行细粒度的内存管理分为
slab、slob、slub三种版本,其中slub是现在通用的版本,其结构如下: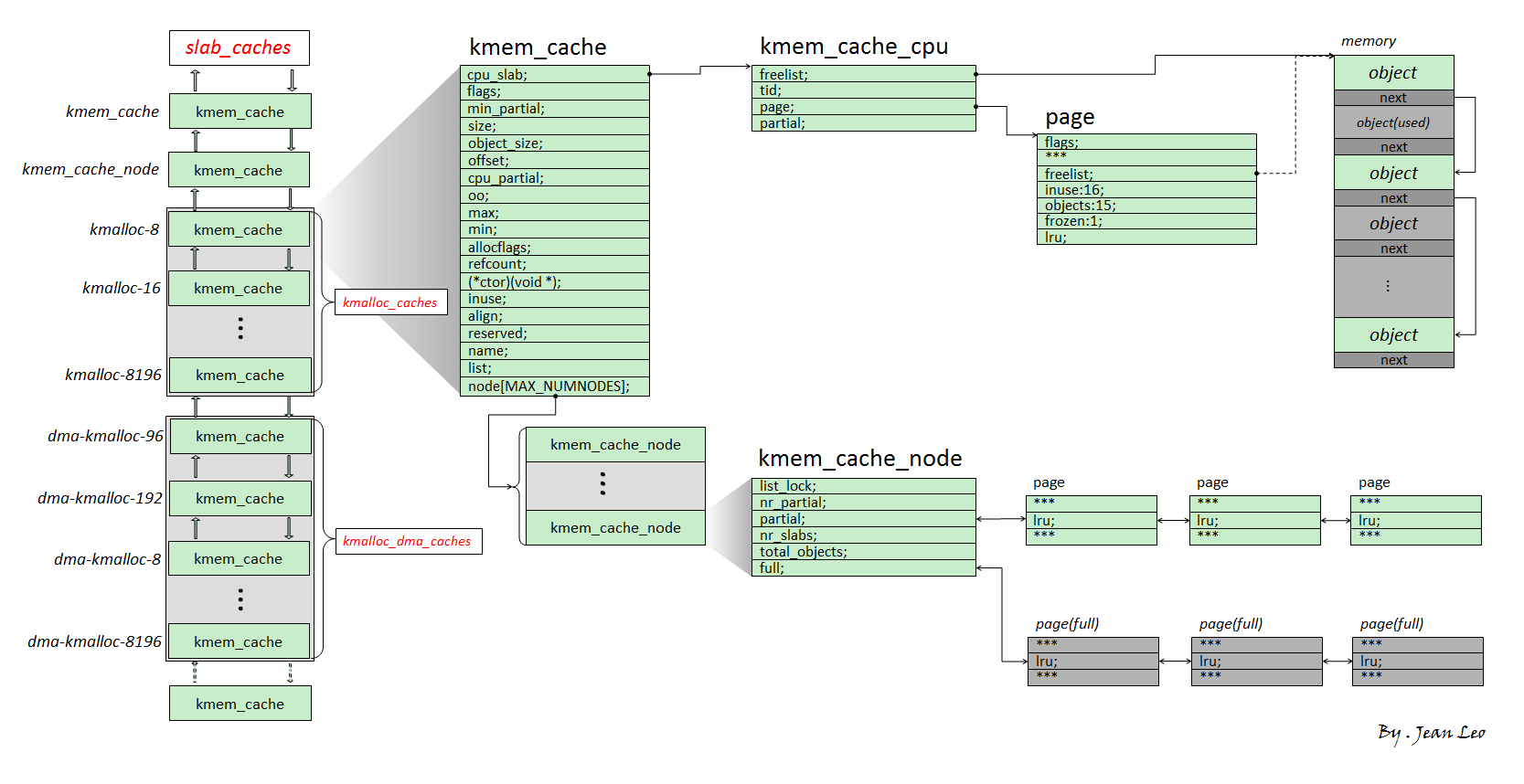
slub的第一张内存页的page结构体的freelist成员指向该张内存页上的第一个空闲对象,一个slub上的所有空闲对象组成一个以NULL结尾的单向链表object类似glibc中的chunk,但是不需要header,因为page结构体与物理内存间存在线性对应关系kmem_cache:基本的allocator组件,用于分配某个特定大小或用途的对象,所有的kmem_cache构成一个双向链表,并存在两个对应的结构体数组kmalloc_caches与kmalloc_dma_caches组成模块:
kmem_cache_cpu:**percpu变量(以gs寄存器作为percpu段的基址,每个核心上都通过段寻址来独立保留一个副本),用以表示当前核心正在使用的slub,因此当前CPU在从kmem_cache_cpu上取object时不需要加锁**,极大地提高了性能kmem_cache_node:当前kmem_cache的slub集散中心,其中存放着两个slub链表:partial:部分object空闲full:所有object都被分配出去
分配:
- 首先从
kmem_cache_cpu上取对象,若有则直接返回 - 若
kmem_cache_cpu上的slub已经无空闲对象了,对应slub会被从kmem_cache_cpu上取下,并尝试从partial链表上取一个slub挂载到kmem_cache_cpu上,然后再取出空闲对象返回 - 若
kmem_cache_node的partial链表也空了,那就向buddy system请求分配新的内存页,划分为多个object之后再给到kmem_cache_cpu,取空闲对象返回上层调用
- 首先从
释放:
- 若被释放
object属于kmem_cache_cpu的slub或kmem_cache_node的partial链表上的slub,直接使用头插法插入当前CPU slub或对应slub的freelist - 若被释放
object为full slub,则成为对应slub的freelist头节点,且该 slub 会被放置到 partial 链表
- 若被释放
slub allocator
kernel UAF
对于释放后未重置的垂悬指针的利用,内核的 “堆内存” 主要指的是直接映射区(direct mapping area)
内核堆利用与绑核
在多核架构下存在多个 kmem_cache_cpu ,利用过程中kernel object的分配有可能会来自不同的 kmem_cache_cpu ,降低了漏洞利用的成功率,因此需要将进程绑定到特定的某个 CPU 核心上,这样 slub allocator 的模型就简化成了 kmem_cache_node + kmem_cache_cpu
进程绑定至指定核心的模板:
#include <sched.h>
/* to run the exp on the specific core only */
void bind_cpu(int core)
{
cpu_set_t cpu_set;
CPU_ZERO(&cpu_set);
CPU_SET(core, &cpu_set);
sched_setaffinity(getpid(), sizeof(cpu_set), &cpu_set);
}通用 kmalloc flag
GFP_KERNEL 、 GFP_KERNEL_ACCOUNT :内核中最为常见与通用的分配 flag,分配都来自同一个 kmem_cache,即通用的 kmalloc-xx
GFP_KERNEL_ACCOUNT 多了一个表示该对象与来自用户空间的数据相关联的属性,因此诸如 msg_msg 、pipe_buffer、sk_buff的数据包的分配使用的都是 GFP_KERNEL_ACCOUNT
而 ldt_struct 、packet_socket 等与用户空间数据没有直接关联的结构体则使用 GFP_KERNEL
在 5.9 版本之前GFP_KERNEL 与 GFP_KERNEL_ACCOUNT 存在隔离机制,后来取消了隔离机制,自内核版本 5.14 起又重新引入:
- 对于开启了
CONFIG_MEMCG_KMEM编译选项的kernel而言(默认开启),会为使用GFP_KERNEL_ACCOUNT进行分配的通用对象创建一组独立的kmem_cache,名为kmalloc-cg-*,从而导致使用这两种flag的object之间的隔离
slub 合并 & 隔离
slab alias机制是一种对同等或相近大小object的 kmem_cache 进行复用的机制
当一个 kmem_cache 在创建时,若已经存在能分配相等或近似大小的 object的 kmem_cache ,则不会创建新的kmem_cache,而是为原有的kmem_cache起一个alias,作为新的kmem_cache返回
对于初始化时设置了 SLAB_ACCOUNT 的 kmem_cache 会新建一个新的 kmem_cache 而非为原有的建立 alias,如在新版的内核当中 cred_jar 与 kmalloc-192 便是两个独立的 kmem_cache,彼此之间互不干扰
Heap Spray
堆喷射(heap spraying):通过大量分配相同的结构体来达成某种特定的内存布局,应用场景:
UAF,无法通过少量内存分配拿到该结构体,例如该object不属于当前freelist且释放后会回到node上,或是像add_key()会被一直卡在第一个临时结构体上,可以通过堆喷射来确保拿到该object- 堆溢出读/写,但是堆布局不可知,比如开启了
SLAB_FREELIST_RANDOM(默认开启),可以预先喷射大量特定结构体,从而保证对其中某个结构体的溢出
freelist劫持
与用户态 glibc 中分配 fake chunk 后覆写 __free_hook 这样的手法类似,我们同样可以通过覆写 freelist 中的 next 指针的方式完成内核空间中任意地址上的对象分配,并修改内核当中一些有用的数据以完成提权,例如一些函数表等
Buddy System
Cross-Cache Overflow & Page-level Heap Fengshui
Cross-Cache Overflow
针对buddy system的利用手法,内存中用作不同kmem_cache的页面内存上可能相邻,若漏洞对象页面与溢出目标对象页面相邻,则可能实现跨越不同kmem_cache之间的堆溢出,但是需要非常严苛的页级堆排布,此时就需要页级堆风水
Page-level Heap Fengshui
以内存页为粒度的内存排布方式,纯手工构造一个新的已知的页级粒度内存页排布
slub allocator 向 buddy system 请求页面的过程,当 freelist page 已经耗空且 partial 链表也为空时(或者 kmem_cache 刚刚创建后进行第一次分配时),其会向 buddy system 申请页面:

buddy system其基本原理就是以 2 的 order 次幂张内存页作为分配粒度,相同 order 间空闲页面构成双向链表,当低阶 order 的页面不够用时便会从高阶 order 取一份连续内存页拆成两半,其中一半挂回当前请求 order 链表,另一半返还给上层调用者
从更高阶 order 拆分成的两份低阶 order 的连续内存页是物理连续的,由此我们可以:
- 向
buddy system请求两份连续的内存页 - 释放其中一份内存页,在
vulnerable kmem_cache上堆喷,让其取走这份内存页 - 释放另一份内存页,在
victim kmem_cache上堆喷,让其取走这份内存页
此时我们便有可能溢出到其他的内核结构体上,从而完成 cross-cache overflow
利用:setsockopt 与 pgv 完成页级内存占位与堆风水
创建一个 protocol 为 PF_PACKET 的 socket 之后,先调用 setsockopt() 将 PACKET_VERSION 设为 TPACKET_V1/ TPACKET_V2,再调用 setsockopt() 提交一个 PACKET_TX_RING ,此时便存在如下调用链:
__sys_setsockopt()
sock->ops->setsockopt()
packet_setsockopt() // case PACKET_TX_RING ↓
packet_set_ring()
alloc_pg_vec()在 alloc_pg_vec() 中会创建一个 pgv 结构体,用以分配 tp_block_nr 份 2^order 张内存页,其中 order 由 tp_block_size 决定:
static struct pgv *alloc_pg_vec(struct tpacket_req *req, int order)
{
unsigned int block_nr = req->tp_block_nr;
struct pgv *pg_vec;
int i;
pg_vec = kcalloc(block_nr, sizeof(struct pgv), GFP_KERNEL | __GFP_NOWARN);
if (unlikely(!pg_vec))
goto out;
for (i = 0; i < block_nr; i++) {
pg_vec[i].buffer = alloc_one_pg_vec_page(order);
if (unlikely(!pg_vec[i].buffer))
goto out_free_pgvec;
}
out:
return pg_vec;
out_free_pgvec:
free_pg_vec(pg_vec, order, block_nr);
pg_vec = NULL;
goto out;
}在 alloc_one_pg_vec_page() 中会直接调用 __get_free_pages() 向 buddy system 请求内存页,因此我们可以利用该函数进行大量的页面请求:
static char *alloc_one_pg_vec_page(unsigned long order)
{
char *buffer;
gfp_t gfp_flags = GFP_KERNEL | __GFP_COMP |
__GFP_ZERO | __GFP_NOWARN | __GFP_NORETRY;
buffer = (char *) __get_free_pages(gfp_flags, order);
if (buffer)
return buffer;
//...
}相应地, pgv 中的页面也会在 socket 被关闭后释放:
packet_release()
packet_set_ring()
free_pg_vec()setsockopt() 也可以帮助我们完成页级堆风水,当我们耗尽 buddy system 中的 low order pages 后,我们再请求的页面便都是物理连续的,因此此时我们再进行 setsockopt() 便相当于获取到了一块近乎物理连续的内存(大量的 setsockopt() 流程中同样会分配大量我们不需要的结构体,从而消耗 buddy system 的部分页面)
Page-level UAF
对内存页结构体 page 的释放后利用,例如可以通过内存页重分配的方式将 UAF page分配为指定 kmem_cache 的 slub pages ,从而实现无需任何限制的跨 kmem_cache 的 UAF 利用
Race Condition
Double Fetch
原理上属于条件竞争漏洞,是一种内核态与用户态之间的数据访问竞争
用户空间向内核传递数据时,内核通过 copy_from_user 等拷贝函数将用户数据拷贝至内核空间,数据复杂时只引用指针
第一次fetch进行校验及相关处理,将数据暂时保存在用户空间,第二次fetch进行数据实际处理
在两次取用数据之间,另一个用户态线程可创造条件竞争,对已通过检查的用户态数据进行篡改,造成内核验证通过数据与实际使用数据不一致形成访问越界或缓冲区溢出
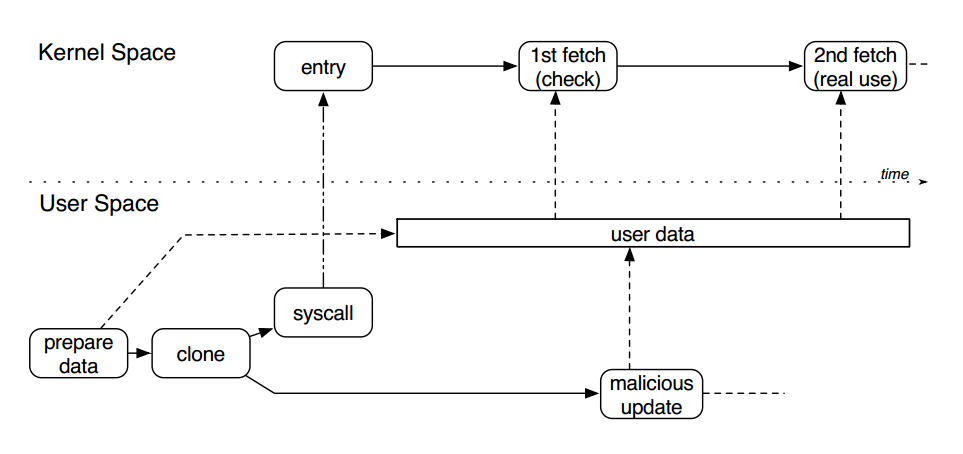
userfaultfd的使用
userfaultfd是一个linux系统调用,用户可以通过自定义的page fault handler在用户态处理缺页异常,流程如下图
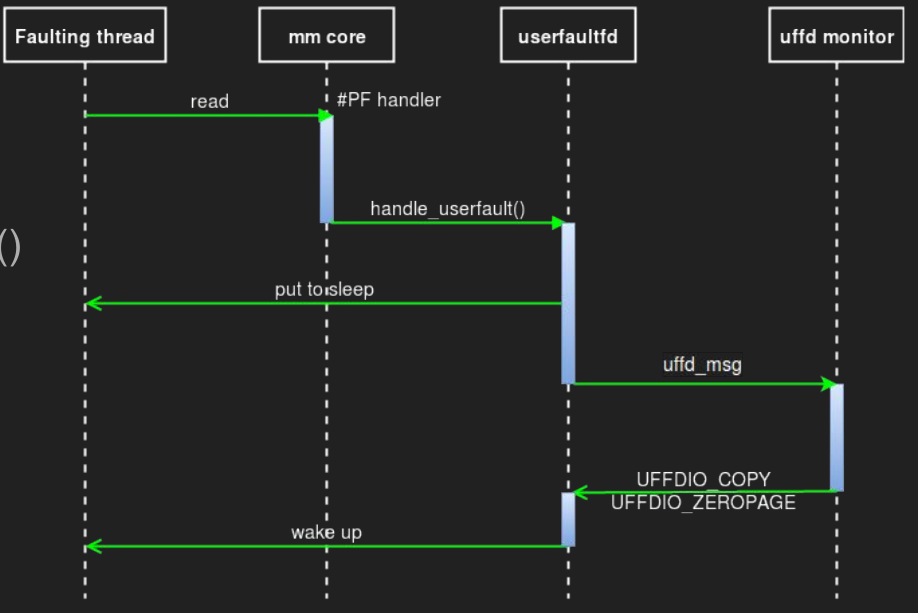
首先要注册一个userfaultfd,通过 ioctl 监视一块内存区域,同时启动一个用以进行轮询的线程 uffd monitor,该线程会通过 poll() 函数不断轮询直到出现缺页异常
- 当有一个线程在这块内存区域内触发缺页异常时(比如说第一次访问一个匿名页),该线程(称之为
faulting线程)进入到内核中处理缺页异常 - 内核会调用
handle_userfault()交由userfaultfd处理 - 随后
faulting线程进入堵塞状态,同时将一个uffd_msg发送给monitor线程,等待其处理结束 monitor线程调用通过ioctl处理缺页异常,有如下选项:UFFDIO_COPY:将用户自定义数据拷贝到faulting page上UFFDIO_ZEROPAGE:将faulting page置0UFFDIO_WAKE:用于配合上面两项中UFFDIO_COPY_MODE_DONTWAKE和UFFDIO_ZEROPAGE_MODE_DONTWAKE模式实现批量填充
- 在处理结束后
monitor线程发送信号唤醒faulting线程继续工作
该机制最初被设计来用以进行虚拟机 / 进程的迁移等用途,但是通过这个机制可以控制进程执行流程的先后顺序,从而使得对条件竞争的利用成功率大幅提高,比如在如下的操作时:
copy_from_user(kptr, user_buf, size);如果在进入函数后,实际拷贝开始前线程被中断换下 CPU,别的线程执行,修改了 kptr 指向的内存块的所有权(比如 kfree 掉了这个内存块),然后再执行拷贝时就可以实现 UAF。这种可能性当然是比较小的,但是如果 user_buf 是一个 mmap 的内存块,并且我们为它注册了 userfaultfd,那么在拷贝时出现缺页异常后此线程会先执行我们注册的处理函数,在处理函数结束前线程一直被暂停,结束后才会执行后面的操作,大大增加了竞争的成功率
使用方法:
在Linux man page当中已经提供了 userfaultfd 的基本使用模板,只需要稍加修改便能直接投入到实战当中,为特定内存注册 userfaultfd monitor 的模板:
void err_exit(char *msg)
{
printf("\033[31m\033[1m[x] Error at: \033[0m%s\n", msg);
exit(EXIT_FAILURE);
}
void register_userfaultfd(pthread_t *monitor_thread, void *addr,
unsigned long len, void *(*handler)(void*))
{
long uffd;
struct uffdio_api uffdio_api;
struct uffdio_register uffdio_register;
int s;
/* Create and enable userfaultfd object */
uffd = syscall(__NR_userfaultfd, O_CLOEXEC | O_NONBLOCK);
if (uffd == -1)
err_exit("userfaultfd");
uffdio_api.api = UFFD_API;
uffdio_api.features = 0;
if (ioctl(uffd, UFFDIO_API, &uffdio_api) == -1)
err_exit("ioctl-UFFDIO_API");
uffdio_register.range.start = (unsigned long) addr;
uffdio_register.range.len = len;
uffdio_register.mode = UFFDIO_REGISTER_MODE_MISSING;
if (ioctl(uffd, UFFDIO_REGISTER, &uffdio_register) == -1)
err_exit("ioctl-UFFDIO_REGISTER");
s = pthread_create(monitor_thread, NULL, handler, (void *) uffd);
if (s != 0)
err_exit("pthread_create");
}可以直接通过如下操作来为一块匿名的 mmap 内存注册 userfaultfd:
register_userfaultfd(thread, addr, len, handler);需要注意的是 handler 的写法:
static char *uffd_src_page = NULL; // 你要拷贝进去的数据
static long uffd_src_page_size = 0x1000;
static void *
fault_handler_thread(void *arg)
{
static struct uffd_msg msg;
static int fault_cnt = 0;
long uffd;
struct uffdio_copy uffdio_copy;
ssize_t nread;
uffd = (long) arg;
for (;;)
{
struct pollfd pollfd;
int nready;
pollfd.fd = uffd;
pollfd.events = POLLIN;
nready = poll(&pollfd, 1, -1);
/*
* [在这停顿.jpg]
* 当 poll 返回时说明出现了缺页异常
* 你可以在这里插入一些比如说 sleep() 一类的操作,
* 例如等待其他进程完成对象的重分配后再重新进行拷贝一类的,也可以直接睡死 :)
*/
if (nready == -1)
errExit("poll");
nread = read(uffd, &msg, sizeof(msg));
if (nread == 0)
errExit("EOF on userfaultfd!\n");
if (nread == -1)
errExit("read");
if (msg.event != UFFD_EVENT_PAGEFAULT)
errExit("Unexpected event on userfaultfd\n");
uffdio_copy.src = (unsigned long) uffd_src_page;
uffdio_copy.dst = (unsigned long) msg.arg.pagefault.address &
~(uffd_src_page_size - 1);
uffdio_copy.len = page_size;
uffdio_copy.mode = 0;
uffdio_copy.copy = 0;
if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1)
errExit("ioctl-UFFDIO_COPY");
}
}Tricks
内存中直接搜索flag
Initial RAM disk(initrd)提供了在 boot loader 阶段载入一个 RAM disk 并挂载为根文件系统的能力,从而在该阶段运行一些用户态程序,在完成该阶段工作之后才是挂载真正的根文件系统
initrd文件系统镜像通常为gzip格式,在启动阶段由boot loader将其路径传给kernel,自2.6版本后出现了使用cpio格式的initramfs,从而无需挂载便能展开为一个文件系统
initrd/initramfs的特点是文件系统中的所有内容都会被读取到内存当中,而大部分 CTF 中的 kernel pwn 题目都选择直接将 initrd 作为根文件系统,因此若是我们有内存搜索能力就能直接在内存空间中搜索flag的内容
